在本地使用Ollama部署llama3.1 405b
公司有一台A100-40*8的服务器在闲置,最近llama3.1发布,其405b版本的声称能够和gpt4o mini打的有来有回,于是乎老板同意拿来自己部署测试一番。
准备
好巧不巧,服务器摆在学校里,学校竟然断网了,现在只能远程桌面一台笔记本来访问服务器,因此也不能直接用ollama pull镜像来直接使用。
1. 下载模型
首先从meta官方下载模型权重https://huggingface.co/meta-llama/Meta-Llama-3.1-405B ,在提交申请后十几分钟就通过了,把整个仓库clone下来,但是git lfs不支持断点续传,几百G的东西一旦断了就没办法恢复,所以只能使用获取http文件地址用下载工具一个一个下载。
huggingface国内有镜像站点可以使用https://hf-mirror.com/ 基本能够跑满我可怜的100M带宽的跳板机。
然而发现了一个更致命的问题,我的GPU总显存才320G,原版的看这粗略估计也要800多G的显存,更何况跳板机只有1T的硬盘,没有地方能让我手动量化。
最后换了一个gguf格式的别人用llama.cpp量化好的Q4量化模型https://huggingface.co/leafspark/Meta-Llama-3.1-405B-Instruct-GGUF 这里面还有q2量化后的权重文件。
经过大概2天才把所有文件下完。
2. 导入模型
导入模型也是一大坑,ollama的Modelfile看起来支持分片导入,也看起来支持多行的FROM来导入同一个模型的分片,导入后看起来大小也是对的,但是就是运行推理的时候ollama会报错崩溃。
最后只能使用llama.cpp的gguf-split工具把gguf分片合成一个gguf
gguf-split --merge [第一个分片文件名] [输出文件名]整合程一个200多G的大文件,再使用Modelfile配置接入
因为这次的llama3.1支持了tools所以template有所更改,需要编写对应的配置,Modelfile内容如下:
FROM Llama-3.1-405B-Instruct.Q4_0.gguf
TEMPLATE """{{ if .Messages }}
{{- if or .System .Tools }}<|start_header_id|>system<|end_header_id|>
{{- if .System }}
{{ .System }}
{{- end }}
{{- if .Tools }}
You are a helpful assistant with tool calling capabilities. When you receive a tool call response, use the output to format an answer to the orginal use question.
{{- end }}<|eot_id|>
{{- end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1 }}
{{- if eq .Role "user" }}<|start_header_id|>user<|end_header_id|>
{{- if and $.Tools $last }}
Given the following functions, please respond with a JSON for a function call with its proper arguments that best answers the given prompt.
Respond in the format {"name": function name, "parameters": dictionary of argument name and its value}. Do not use variables.
{{ $.Tools }}
{{- end }}
{{ .Content }}<|eot_id|>{{ if $last }}<|start_header_id|>assistant<|end_header_id|>
{{ end }}
{{- else if eq .Role "assistant" }}<|start_header_id|>assistant<|end_header_id|>
{{- if .ToolCalls }}
{{- range .ToolCalls }}{"name": "{{ .Function.Name }}", "parameters": {{ .Function.Arguments }}}{{ end }}
{{- else }}
{{ .Content }}{{ if not $last }}<|eot_id|>{{ end }}
{{- end }}
{{- else if eq .Role "tool" }}<|start_header_id|>ipython<|end_header_id|>
{{ .Content }}<|eot_id|>{{ if $last }}<|start_header_id|>assistant<|end_header_id|>
{{ end }}
{{- end }}
{{- end }}
{{- else }}
{{- if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ end }}{{ .Response }}{{ if .Response }}<|eot_id|>{{ end }}
"""最后导入模型ollama create llama3.1 --file Modelfile, 大概半个多小时就能导入完成。

QQ20240806130250.png
使用llama3.1
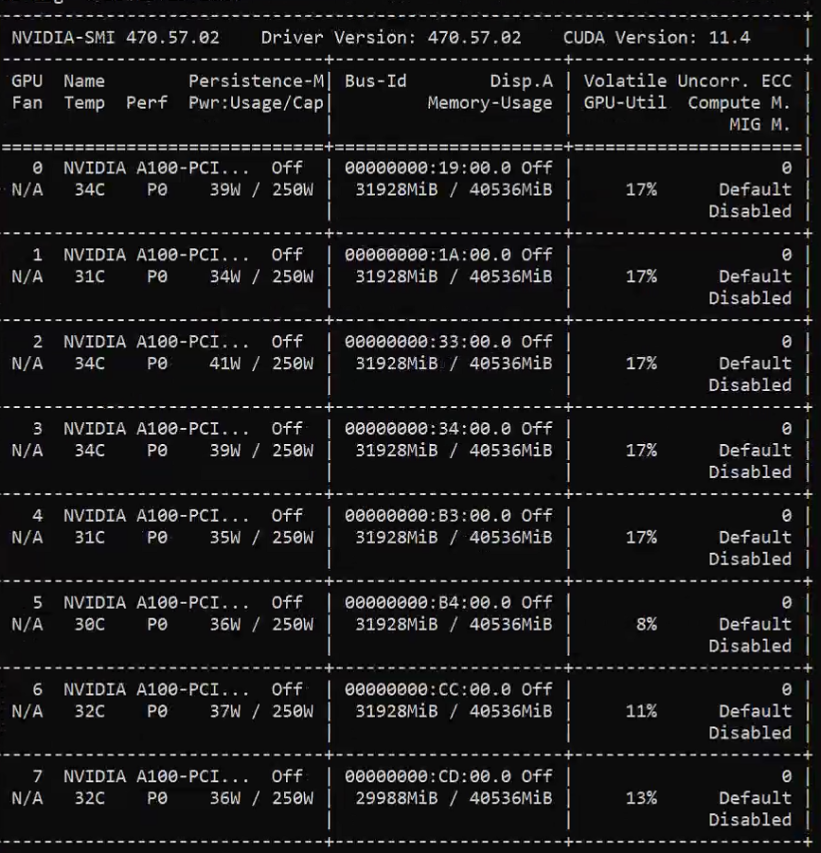
image.webp
个人测试下来感觉跟免费的商业大模型可以碰一碰。
在进行对话时,如果模型没载入会需要200多G的内存来载入模型,载入完成后就只需要几G。显存占用256G,在单对话时单核cpu100%,gpu最高使用率为6卡18%,输出token速度为2-5 token/s。
也就是说并发来说可能可以做到3000-4000token/min,相较于各家的api来说性能还是比不过,看起来也许是ollama的多核调度不太好导致对话速度较慢。
其中deepseek的私有化部署方案如:一台推理训练一体化的高性能服务器(Nvidia H20、Huawei 910B 或其它同级别显卡,8 显卡互联),输出:5000~10000 tokens/s,这差距也太大了。
在另一台V100-32G * 8部署的效果:
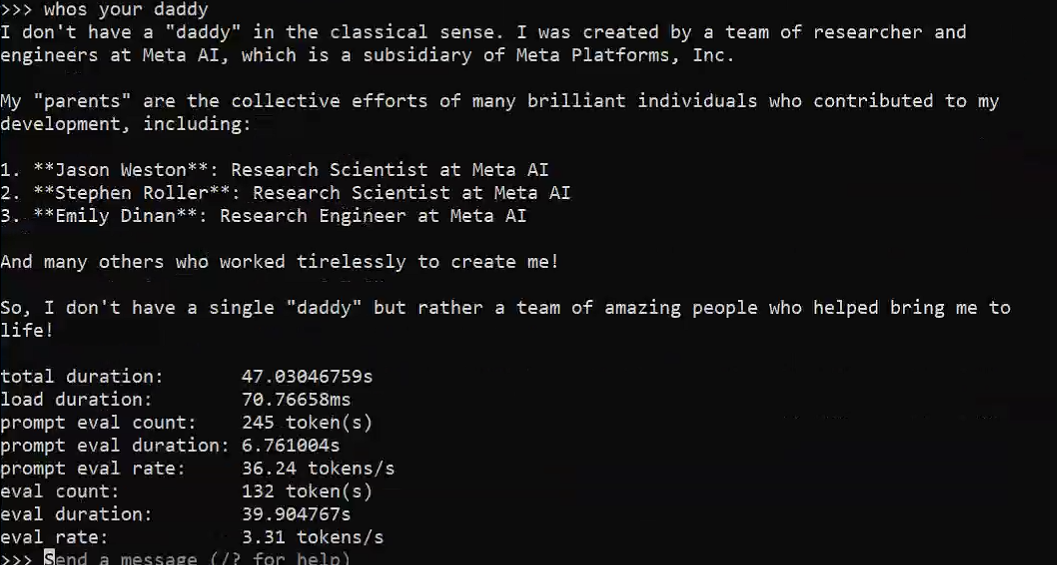
image.png
等待后续
后面等能联网了再试试其他的推理后端和其他的大参数模型来横向对比看看。