使用GraphRAG构建自己的知识库
GraphRAG是微软开源的一个利用知识图谱和LLM来处理大量文本的工具,其能在大量文本中利用LLM来提取实体(Entities)和关联关系(Relationships)并创建索引,这种方法使得比起传统的文章切片后直接使用词嵌入后存入向量数据库有更精准的信息搜索结果,能大幅提高LLM的回答效果。
准备使用
安装graphrag,只支持python3.10及以上的版本,太老的需要先更换python版本
python -m venv venv
source venv/bin/activate
pip install graphrag创建仓库
创建数据库并初始化,graphrag只支持txt和csv两种格式,需要将txt格式的文件放入input文件夹中。
mkdir books && cd books
mkdir input
python -m graphrag.index --init --root .配置仓库
初始化后在books目录下会有.env和settings.yaml两个配置文件。
首先打开settings.yaml进行配置llm大语言模型部分
encoding_model: cl100k_base
skip_workflows: []
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_chat # openai格式接口或者azure格式使用azure_openai_chat
model: deepseek-chat # 模型名称
model_supports_json: true # 接口是否支持强制json格式输出
# max_tokens: 4000 # 最大输出token,大部分都是4k
# request_timeout: 180.0
api_base: https://api.deepseek.com/ # api接口,一般都写到/v1为止,deepseek没有/v1
# api_version: 2024-02-15-preview
# organization:
# deployment_name:
# tokens_per_minute: 150_000 # set a leaky bucket throttle
requests_per_minute: 100 # 限制llm api请求
# max_retries: 10
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times
# concurrent_requests: 25 # 并发处理数量
# temperature: 0 # temperature for sampling
# top_p: 1 # top-p sampling
# n: 1 # Number of completions to generate在这里我使用DeepSeek作为LLM后端,最主要原因是他便宜,gpt4o-mini输入价格差不多输出贵一倍,但是DeepSeek现在它提供api缓存功能,相同的prompt命中缓存后只需要0.1元/M token,对于GraphRAG来说这是一个很省钱的一个特性,在创建索引阶段大概有50%-70%能够命中缓存,这么高的比例真的是太香了,而且在后续搜索过程中还会用到很多重复的token。如果没有缓存的话换其他LLM成本大概还得提升50%。
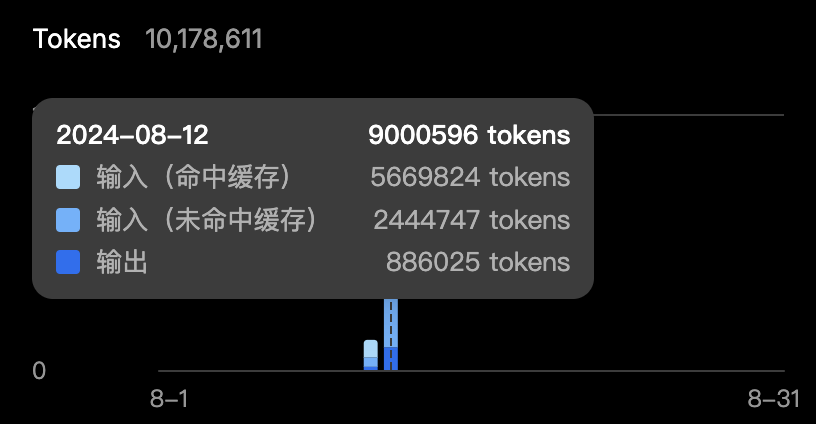
deepseek token用量
同时DS的API是没有频率、并发限制的。
虽然DeepSeek已经足够省钱,但是如果追求极致白嫖的话只能自己部署LLM了Ollama、vllm、llamafile、llama.cpp现在都能很方便的部署,但是根据之前的测试如果想要达到GPT 4o的效果部署llama3.1 405b Q4的话需要使用256GVRAM实测tps只有3-4,deepseek v2也要大约40G,普通显卡可能只能部署一个7b模型。
最先考虑的是tps,因为graphrag是需要将整个文本送入llm进行分析的,如果tps太低那要跑到天荒地老。
配置词嵌入embedding部分:
embeddings:
## parallelization: override the global parallelization settings for embeddings
async_mode: threaded # or asyncio
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_embedding # openai格式接口或者azure格式使用azure_openai_chat
model: shaw/dmeta-embedding-zh
api_base: http://127.0.0.1:11434/v1
# api_version: 2024-02-15-preview
# organization:
# deployment_name:
# tokens_per_minute: 150_000 # set a leaky bucket throttle
# requests_per_minute: 10_000 # set a leaky bucket throttle
# max_retries: 10
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times
concurrent_requests: 2 # 并发数量
# batch_size: 16 # the number of documents to send in a single request
# batch_max_tokens: 8191 # the maximum number of tokens to send in a single request
# target: required # or optional词嵌入可以本地部署一个embedding模型,不需要商用大模型,一般开源模型几百M参数的性能已经不错了,用CPU跑也是很快的。
可以看看MTEB榜单选择模型https://huggingface.co/spaces/mteb/leaderboard ,在这里中文推荐xiaobu-embedding-v2,只要1.2G的VRAM就能达到榜首,但是不知道这个模型对英文的分类效果怎么样。
最后将api key写入.env后GRAPHRAG_API_KEY就可以开始使用了
开始索引
python -m graphrag.index --root .我塞了大概10MB的小说进去,期间因为各种理由中断了好几次。在索引时会在output下创建最新的文件夹就是本次任务的数据,使用--resume 20241506-0123参数可以从中断处继续索引。
10M的文本大概跑了一个下午,具体token使用量已经无法统计了,因为切换了好几次模型也没用resume参数导致重复跑了很多token,前5MB在DeepSeek大概用了1100万tokens。
开始使用
全局(Global)搜索
传统RAG在仅使用向量数据库的情况下是无法做到聚合数据查询的,他只能提取和提问最相关的数据条目。
而GraphRAG在索引后创建了一套数据体系,使得可以使数据组织成有意义的聚合输出给LLM。因此可以用来提出一些更笼统的问题。
python -m graphrag.query \
--root . \
--method global \
"这个故事的主题是什么"本地(local)搜索
在使用本地搜索时与传统向量数据库类似,但是GraphRAG还会调用相关联的数据实体,使其数据更充分完整。
python -m graphrag.query \
--root . \
--method local \
"主角的能力是什么,是怎么获得的"现在就拥有了自己的知识库了,搜集来的东西直接往里面丢,但是现在只支持txt的话还是有点麻烦,官方也表示pdf啊html啊格式太多太乱了,不想做。
使用时的小问题
在使用local查询时使用开源模型时会发生错误
Error embedding chunk {'OpenAIEmbedding': 'Error code: 400 - {'error': "'input' field must be a string or an array of strings"}'}原因是GraphRAG对于开源的词嵌入模型兼容有点问题,需要手动修改graphrag/query/llm/oai/embedding.py 找到embed函数
...
def embed(self, text: str, **kwargs: Any) -> list[float]:
"""
Embed text using OpenAI Embedding's sync function.
For text longer than max_tokens, chunk texts into max_tokens, embed each chunk, then combine using weighted average.
Please refer to: https://github.com/openai/openai-cookbook/blob/main/examples/Embedding_long_inputs.ipynb
"""
token_chunks = chunk_text(
text=text, token_encoder=self.token_encoder, max_tokens=self.max_tokens
)
chunk_embeddings = []
chunk_lens = []
for chunk in token_chunks:
# 添加这行 decode chunk from token ids to text (added line after row 83)
chunk = self.token_encoder.decode(chunk)
try:
embedding, chunk_len = self._embed_with_retry(chunk, **kwargs)
chunk_embeddings.append(embedding)
chunk_lens.append(chunk_len)
# TODO: catch a more specific exception
except Exception as e: # noqa BLE001
self._reporter.error(
message="Error embedding chunk",
details={self.__class__.__name__: str(e)},
)
continue
chunk_embeddings = np.average(chunk_embeddings, axis=0, weights=chunk_lens)
chunk_embeddings = chunk_embeddings / np.linalg.norm(chunk_embeddings)
return chunk_embeddings.tolist()
...