Qwen2.5的小小部署测试
最近阿里新开源的Qwen2.5性能测试真是出乎意料,不光是一口气推出了0.5B、1.5B、3B、7B、14B、32B、72B一共7种参数尺寸的模型,同时还有针对数学和编码转门优化过的专门模型,尤其是72B的测试结果更是可以和llama3.1 405b掰掰手腕。32B也在大部分测试项目中超过了gpt4o-mini。
除了3B和72B外是属于Qwen Research License,其他都是Apache 2.0,所以其他的都可以商业使用。
测试结果都展现在官方页面中 https://qwenlm.github.io/blog/qwen2.5-llm/ 。
这里摘抄一点测试表格内容:
官方测试内容
这里的测试内容包括
通用任务: MMLU-Pro, MMLU-redux
数学和科学任务: GPQA, GSM8K, MATH
编码任务: HumanEval, MBPP, MultiPL-E, LiveCodeBench 2305-2409, LiveBench 0831
指令微调&对齐任务: IFeval strict-prompt, Arena-Hard, AlignBench v1.1, MTbench
Qwen2.5-72B-Instruct Performance
| Datasets | Mistral-Large2 Instruct | Llama-3.1-70B-Instruct | Llama-3.1-405B-Instruct | Qwen2-72B-Instruct | Qwen2.5-72B-Instruct |
|---|---|---|---|---|---|
| MMLU-Pro | 69.4 | 66.4 | 73.3 | 64.4 | 71.1 |
| MMLU-redux | 83.0 | 83.0 | 86.2 | 81.6 | 86.8 |
| GPQA | 52.0 | 46.7 | 51.1 | 42.4 | 49.0 |
| MATH | 69.9 | 68.0 | 73.8 | 69.0 | 83.1 |
| GSM8K | 92.7 | 95.1 | 96.8 | 93.2 | 95.8 |
| HumanEval | 92.1 | 80.5 | 89.0 | 86.0 | 86.6 |
| MBPP | 80.0 | 84.2 | 84.5 | 80.2 | 88.2 |
| MultiPL-E | 76.9 | 68.2 | 73.5 | 69.2 | 75.1 |
| LiveCodeBench 2305-2409 | 42.2 | 32.1 | 41.6 | 32.2 | 55.5 |
| LiveBench 0831 | 48.5 | 46.6 | 53.2 | 41.5 | 52.3 |
| IFeval strict-prompt | 64.1 | 83.6 | 86.0 | 77.6 | 84.1 |
| Arena-Hard | 73.1 | 55.7 | 69.3 | 48.1 | 81.2 |
| AlignBench v1.1 | 7.69 | 5.94 | 5.95 | 8.15 | 8.16 |
| MTbench | 8.61 | 8.79 | 9.08 | 9.12 | 9.35 |
Qwen-Turbo & Qwen2.5-14B-Instruct & Qwen2.5-32B-Instruct Performance
| Datasets | Qwen2-57B-A14B-Instruct | Gemma2-27B-IT | GPT4o-mini | Qwen-Turbo | Qwen2.5-14B-Instruct | Qwen2.5-32B-Instruct |
|---|---|---|---|---|---|---|
| MMLU-Pro | 52.8 | 55.5 | 63.1 | 64.8 | 63.7 | 69.0 |
| MMLU-redux | 72.6 | 75.7 | 81.5 | 80.4 | 80.0 | 83.9 |
| GPQA | 34.3 | 38.4 | 40.2 | 44.4 | 45.5 | 49.5 |
| MATH | 49.1 | 54.4 | 70.2 | 81.0 | 80.0 | 83.1 |
| GSM8K | 85.3 | 90.4 | 93.2 | 93.6 | 94.8 | 95.9 |
| HumanEval | 79.9 | 78.7 | 88.4 | 86.6 | 83.5 | 88.4 |
| MBPP | 70.9 | 81.0 | 85.7 | 80.2 | 82.0 | 84.0 |
| MultiPL-E | 66.4 | 67.4 | 75.0 | 73.0 | 72.8 | 75.4 |
| LiveCodeBench 2305-2409 | 22.5 | - | 40.7 | 43.1 | 42.6 | 51.2 |
| LiveBench 0831 | 31.1 | 39.6 | 43.3 | 41.6 | 44.4 | 50.7 |
| IFeval strict-prompt | 59.9 | 77.1 | 80.4 | 74.9 | 81.0 | 79.5 |
| Arena-Hard | 17.8 | 57.5 | 74.9 | 68.4 | 68.3 | 74.5 |
| AlignBench v1.1 | 7.02 | 7.22 | 7.81 | 7.99 | 7.94 | 7.93 |
| MTbench | 8.55 | 9.10 | - | 8.86 | 8.88 | 9.20 |
其他平台测试结果
如果不信官方的结果的话可以看看https://artificialanalysis.ai/models/qwen2-5-72b-instruct/providers,结果上和官方提供的差不多。
其他人的量化性能测试结果
https://www.reddit.com/r/LocalLLaMA/comments/1fkm5vd/qwen25_32b_gguf_evaluation_results/
根据reddit老哥的测试结果,以Q4_K_L-iMatrix为基准。Q3_K_M量化似乎没有质量损失(单指MMLU PRO任务),但是权重大小从20.43GB降到了14.8GB。这说明16G的家用卡也能完全load起来。
并且光是Q3量化的就已经打爆了Gemma2-27b q8量化。
自己的部署测试结果
因为公司的A100-40G有人用,只能放在V100-32G上测试。
软件环境:
- 32b-instruct-q4_K_M
- Ollama 0.3.11
加载完成后占用23G显存:
NAME ID SIZE PROCESSOR UNTIL
qwen2.5:32b 9f13ba1299af 23 GB 100% GPU Forever(看起来还可以在同时跑一个14b或者7b去运行一些小任务?)
单任务速度如下:
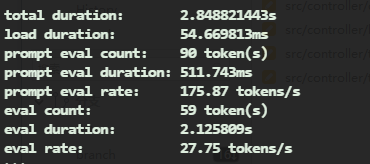
Test in V100-32G
开启并发支持后同时发送测试性能:
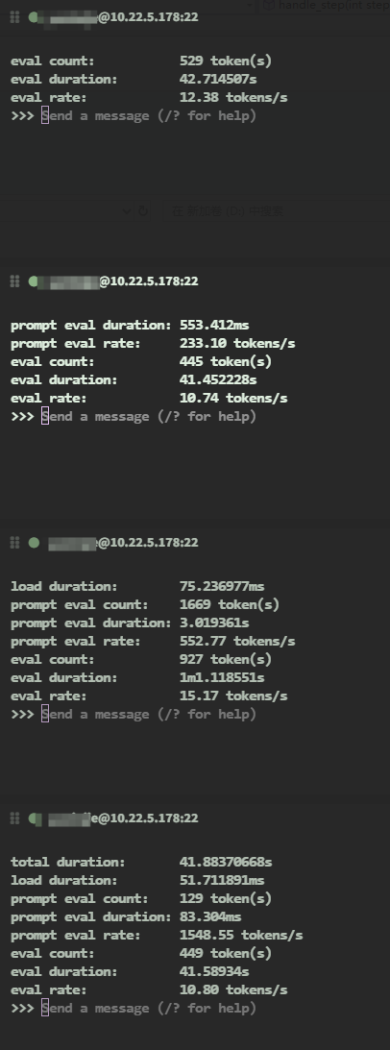
image.webp
总体性能可能在到40-47 t/s的样子
成本分析上来说比gpt4o-mini贵50%,0.381/M Tokens。
根据我自己测算的性能按照单卡40t/s来算,V100-32G一直跑满250W,电费的话我也不太清楚(因为是放到学校里去了,也不知道要不要收我们维护费,但是机器都是公司买的,应该也行不收吧),按1块钱一度来算,1M tokens要6.944 GPU hour,电费成本大概就是¥6.944/M Tokens。
看起来比Artificial Analysis推算的价格高好多,不过也是V100不是出生在大模型的年代,肯定没有现在的H100、H20推理效率那么高,等后面有空再试试Q3的推理速度。
总结
Qwen2.5这次是一次巨大的提升,并没有像llama3.1那样靠超大的参数来硬拉(更何况llama3.1的多语言支持就是一坨),在各项测试成绩中都是处于不错甚至是前列的地位,并且经过量化后可以运行在大量的设备上,更何况他本来就提供小参数模型,各位可以看需求选取合适自己的模型,我会推荐老板在公司服务器上拿4张V100来跑32b给公司里有需要的人使用(老板之前openai用的心疼,把gpt4都下掉了,只给4o和4o-mini用),大概可以达到160-200t/s的速度。
另外要提一嘴排除o1,我并不认为o1是单独的一个大模型,他更像是使用了cot的一个工程优化后的大模型,不光是token的单价和4刚出的时候差不多(60 out你敢信),使用了cot token使用量也会大幅提升,所以这成本谁能用的起。如果其他llm也用上cot之后,回答质量和o1会差多少也不好说呢。