AnimeApi随机二次元壁纸图片项目(二)查询速度优化
在这个项目中我仅使用了MongoDB来存储图片的元信息。在项目刚开始时并没有多少请求,所以MongoDB的Query速度并没有多少影响,但到了如今每月1M次请求的情况下,查询速度已经是不可回避的问题了。
原始Document Sample 图片元信息
在mongo中存在的最新基本格式如下,不同时间段的数据会有些许差异,部分字段并未开放到API中。
{
"_id": 322412,
"created_at": 1611707779,
"creator_id": 210352,
"author": "Arsy",
"change": 1971738,
"source": "あまあまメイドの特別レッスン♪",
"score": 6,
"md5": "111c6a15dbad170d6944a4a0db1c041d",
"file_size": 2902416,
"file_url": "https://konachan.com/image/111c6a15dbad170d6944a4a0db1c041d/Konachan.com%20-%20322412%20breasts%20brown_hair%20cleavage%20flowers%20headdress%20long_hair%20maid%20original%20thighhighs%20y_umiharu.jpg",
"is_shown_in_index": true,
"preview_url": "https://konachan.com/data/preview/11/1c/111c6a15dbad170d6944a4a0db1c041d.jpg",
"preview_width": 150,
"preview_height": 113,
"actual_preview_width": 300,
"actual_preview_height": 225,
"sample_url": "https://konachan.com/sample/111c6a15dbad170d6944a4a0db1c041d/Konachan.com%20-%20322412%20sample.jpg",
"sample_width": 1500,
"sample_height": 1125,
"sample_file_size": 824134,
"jpeg_url": "https://konachan.com/image/111c6a15dbad170d6944a4a0db1c041d/Konachan.com%20-%20322412%20breasts%20brown_hair%20cleavage%20flowers%20headdress%20long_hair%20maid%20original%20thighhighs%20y_umiharu.jpg",
"jpeg_width": 2560,
"jpeg_height": 1920,
"jpeg_file_size": 0,
"rating": "s",
"has_children": false,
"parent_id": null,
"status": "active",
"width": 2560,
"height": 1920,
"is_held": false,
"frames_pending_string": "",
"frames_pending": [],
"frames_string": "",
"frames": [],
"tags": [
"breasts",
"brown_hair",
"cleavage",
"flowers",
"headdress",
"long_hair",
"maid",
"original",
"thighhighs",
"y_umiharu"
],
"rating_on_ml": "s"
}分析原始查询
数据库相关代码存在于src/database/handler.rs
查询使用Aggregations Pipeline进行数据查询。
stage1的条件为rating_on_ml深度学习网络的等级标注为s,created_at图片创建时间大于1506787200,file_size文件大小在500到12MB之间,图片的宽高在640到6144之间。
stage2同时根据查询条件横向或纵向,添加阶段2判断图片的宽高比例。
最后使用sample采样一份图片元信息通过API返回。
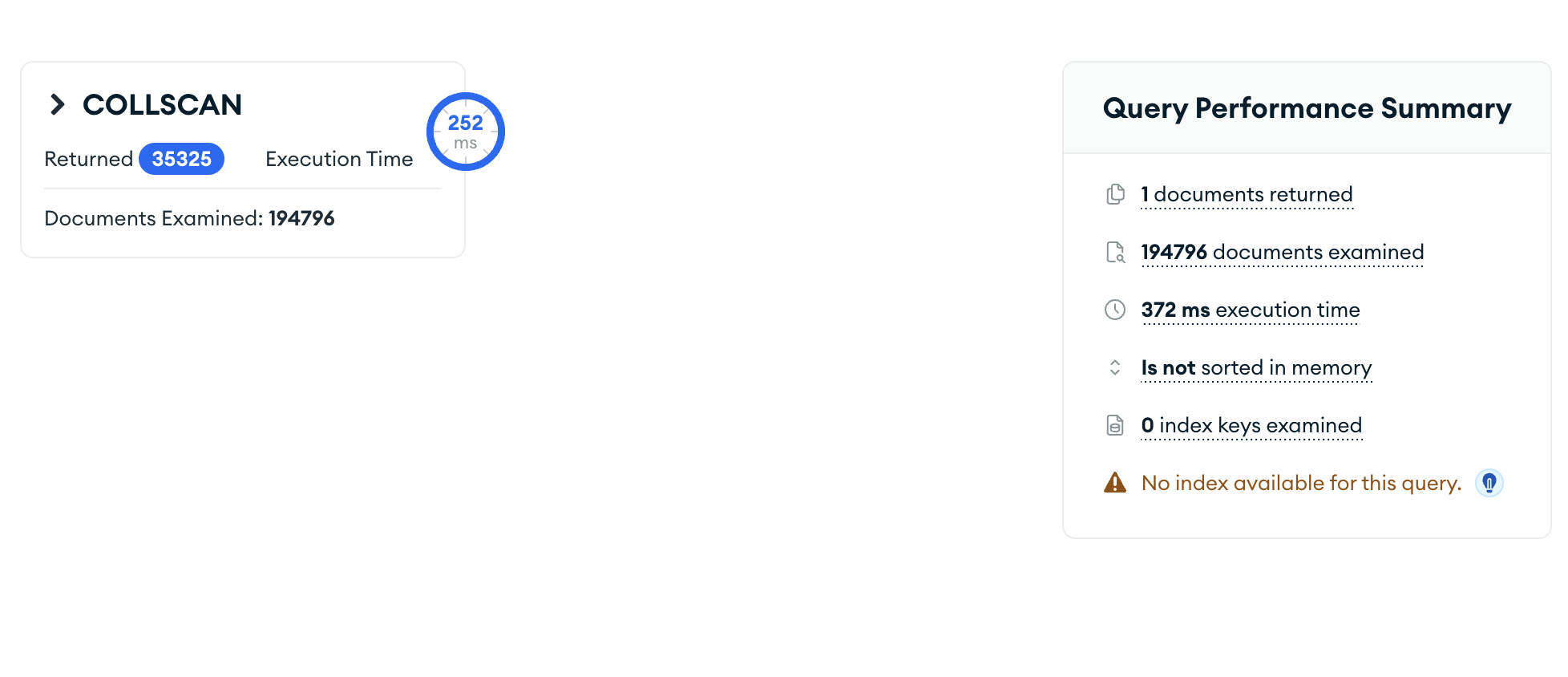
image.png
在默认情况无优化的情况花费372ms
MongoDB查询优化
最方便的优化方式那就是加索引了,基本不需要修改就能获得很大的提升。但是使用export导出后迁移数据库的情况貌似不会导出索引,现在在新的服务器上竟然没有索引跑了一个月。
狂加索引
既然聚合查询的第一步要那么多参数,那直接把用到的字段全加到一个索引里面是不是就行了。
那么就来试试,将stage1的所有用到的字段全部加入到一个索引内。
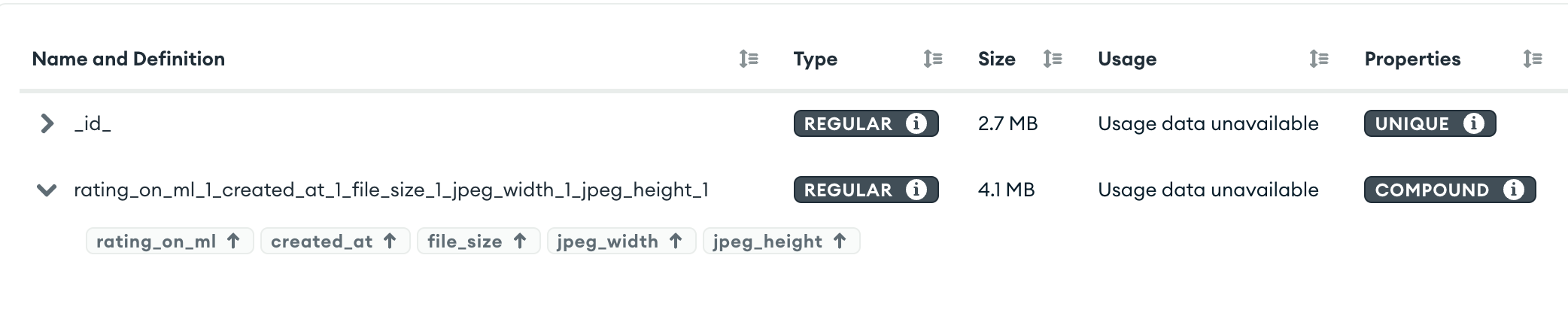
image.png
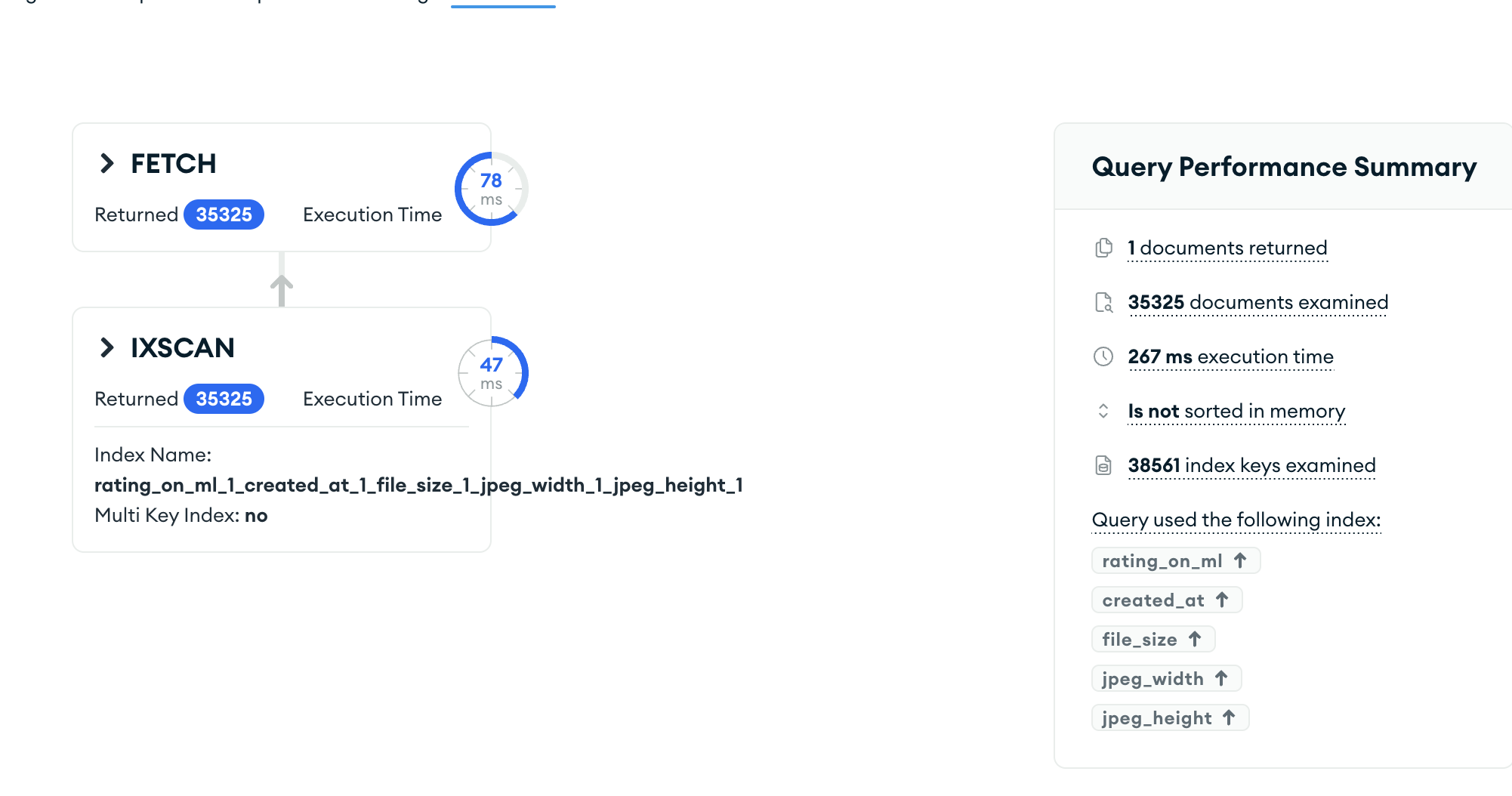
image.png
由于使用了索引,查询性能得到了明显的提升。检查的索引键总数为38561,返回的文档数量为35325,索引过滤了大量的文档,减少了需要检查的文档数量。
优化器自动选择了最佳的执行计划,即使用复合索引进行查询,而不是全表扫描或其他索引。$expr阶段的$gt:["$jpeg_width", "$jpeg_height"]条件没有用上索引,因为它需要在文档级别进行计算。大约有30%的性能提升,但是相比人体感官来说与无索引的360ms似乎区别又不是很大。所以需要继续尝试优化。
优化$expr
从数据库层来优化基本是不可能的了,因为索引只会用在过滤类的操作上,其他的例如使用$addFields的操作
/**
* 给文档添加is_landscape字段宽度是否大于高度
*/
{
is_landscape: { $gt: ["$jpeg_width", "$jpeg_height"] }
}基本上和expr操作是一样的,都会逐个对文档进行重新计算,因此最好的方法是添加一步预处理操作,提前计算好写入数据库。再放入索引中,match就会使用索引获得更好的性能。
更新所有文档
db.collection.updateMany(
{},
[
{
$set: {
is_landscape: { $expr: { $gt: [ "$jpeg_width", "$jpeg_height" ] } }
}
}
]
)这样所有的文档就会多出一个is_landscape字段来表示是横幅还是纵幅。
经过这么一操作那么速度一定大有提升吧!
然而事实却是如此
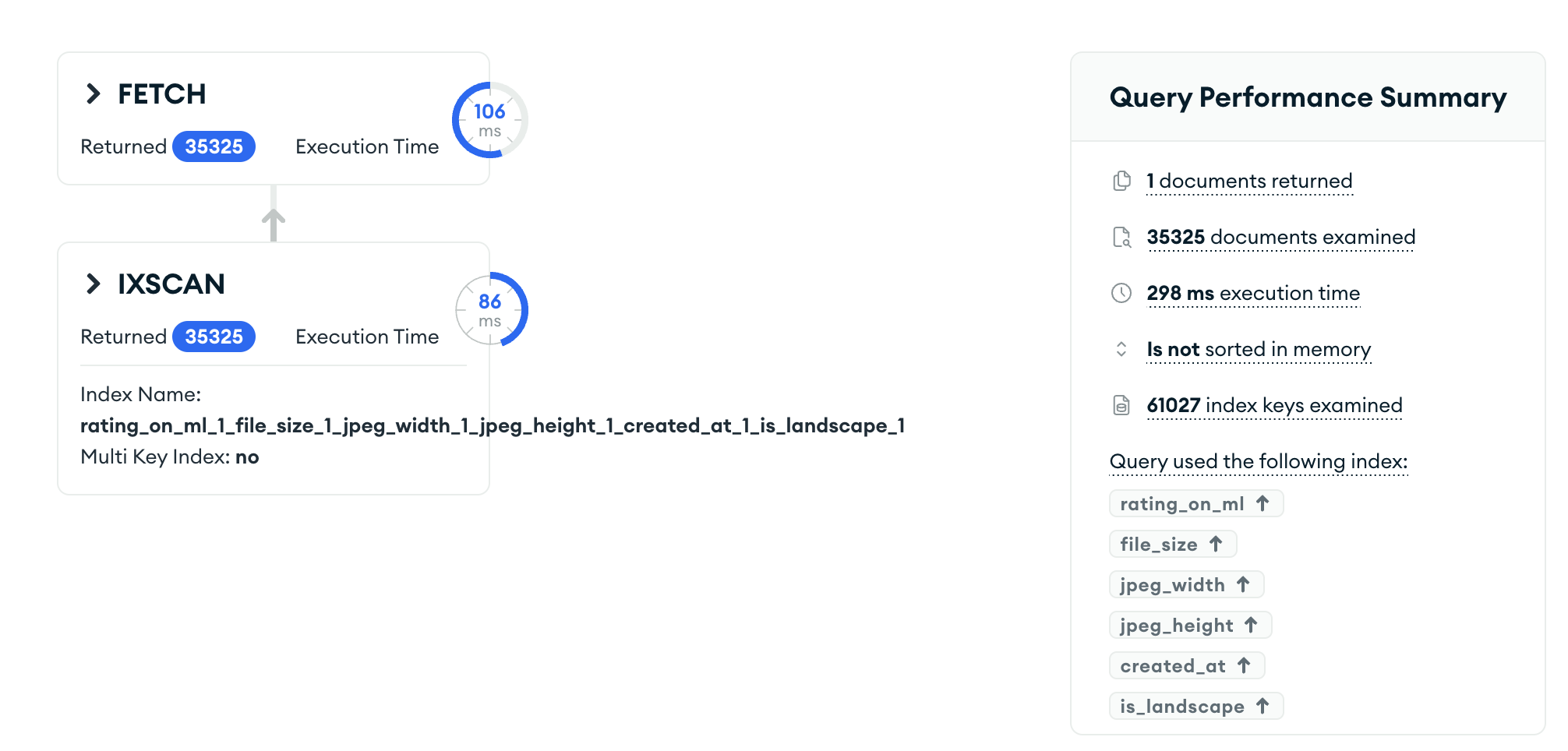
image.png
并没有提升速度反而下降了,可以看到查询使用到的索引大小变大了达到了61027,原因应该是因为is_landscape符合条件所包含的文档更多,导致索引查询的数量变大,导致总体的查询效率降低了。
在同时拥有
rating_on_ml,create_at,file_size,jpeg_width,jpeg_heightrating_on_ml,create_at,file_size,jpeg_width,jpeg_height,is_landscape的情况下,优化器直接就选择了第一条,他也知道下面的不会有好结果
所以优化这项失败,只能另寻他法。
增加查询缓存
观察请求结构,发现绝大部分请求都是在使用默认查询参数,因此可以从此下手进行优化。
缓存设计与实现
我们选择在应用层实现一个简单的查询缓存,利用OnceCell持有Arc<Mutex<HashMap<String, Vec<ImageDetail>>>>,这是一个线程安全的缓存结构,确保在多线程环境下对缓存的操作不会产生竞争条件。
static QUERY_CACHE: OnceCell<Arc<Mutex<HashMap<String, Vec<ImageDetail>>>>> = OnceCell::const_new();缓存键的生成
为了确保每个不同的查询参数组合都能对应到唯一的缓存键,我们根据查询参数生成一个唯一的字符串键。最快速的方法就是直接将所有的参数拼接到一起,以生成缓存键。
impl SearchCondition{
pub fn toHex(&self)->String{
let mut hex = String::new();
hex.push_str("0x");
hex.push_str(&format!("{:x}",self.id.clone().unwrap_or(0)));
hex.push_str(&format!("{:x}",self.exclude_tags.clone().unwrap_or(Vec::new()).iter().fold(0,|acc,x|acc+x.len())));
hex.push_str(&format!("{:x}",self.include_tags.clone().unwrap_or(Vec::new()).iter().fold(0,|acc,x|acc+x.len())));
hex.push_str(&format!("{:x}",self.horizontal.clone().unwrap_or(false) as u8));
hex.push_str(&format!("{:x}",self.compress.clone().unwrap_or(true) as u8));
hex.push_str(&format!("{:x}",self.min_size));
hex.push_str(&format!("{:x}",self.max_size));
hex
}
}这个缓存结构会储存下不同请求参数的返回的图片Meta,而在Mongo的查询中我们将sample的参数改成100,所以每次有不同的请求参数,都会直接在数据库中采样100条图片,并储存到缓存中,之后的请求在这个缓存中查询是否有意义的查询条件,有一样的话就直接从缓存中读取信息。
因此这样做之后平均查询延迟就变成了260/100=2.6ms,在缓存中的查询延迟基本可以忽略不计了,所以从最开始的360ms优化到了2.6ms!
结论
我们可以需要根据各个项目的特性来针对性优化请求的处理方式来提升响应速度,就例如我这个随机接口对于数据的实时性不高,因此就可以减少实际的MongoDB查询次数降低数据库负载,同时还能大幅提升响应时间。