使用腾讯的NCNN框架推理YOLOX
ncnn是腾讯自己开发的一款开源神经网络推理框架,从设计之初就是为了手机端的应用,现在已经支持全平台(Android、鸿蒙、iOS、MacOS、Linux)、(x86、ARM、riscv、loongarch),提供的预编译二进制文件基本上是囊括了市面上能见到的所有系统和架构,如果没有还能自己编译需要的版本 https://github.com/Tencent/ncnn/wiki/how-to-build
纯C++、无第三方库,还支持大小核调度优化,并且支持Vulkan API GPU 加速!
适用性多么好我就不说了,简直就是,具体可以看官方的README https://github.com/Tencent/ncnn
原本我是使用了OpenCV的DNN来推理,但是官方发布的预编译文件不提供包含CUDA,所以都得手动编译来获得CUDA加速特性。而且平时使用时经常会更换CUDA版本,为此还得给每个版本都编译一个OpenCV,不仅是CUDA版本,OpenCV在版本之间也是不兼容的,所以现在使用的预编译好的库早已是八百年前的版本。在发布时还得带上CUDA Runtime,整个系统包就显得十分臃肿。
尽早脱离编译苦海才是正道,所以ncnn简直是完美的替代方案。
使用前准备
首先下载ncnn提供的预编译文件:https://github.com/Tencent/ncnn/releases
根据自己的目标来下载,里面包含了二进制库文件,还有工具文件
比如下载了windows的预编译包,则包含arm、arm64、x64、x86四种架构的预编译文件
├─arm
│ ├─bin
│ ├─include
│ │ └─ncnn
│ └─lib
│ ├─cmake
│ │ └─ncnn
│ └─pkgconfig
├─arm64
│ ├─bin
│ ├─include
│ │ └─ncnn
│ └─lib
│ ├─cmake
│ │ └─ncnn
│ └─pkgconfig
├─x64
│ ├─bin
│ ├─include
│ │ └─ncnn
│ └─lib
│ ├─cmake
│ │ └─ncnn
│ └─pkgconfig
└─x86
├─bin
├─include
│ └─ncnn
└─lib
├─cmake
│ └─ncnn
└─pkgconfig每个架构下都提供了编译完成的库文件和工具文件,内含一系列的模型转换工具、量化工具、优化模型文件工具和合并模型文件工具等。
caffe2ncnn.exe
darknet2ncnn.exe
mxnet2ncnn.exe
ncnn.dll
ncnn2int8.exe
ncnn2mem.exe
ncnn2table.exe
ncnnmerge.exe
ncnnoptimize.exe
onnx2ncnn.exe转化模型
首先将yolox训练完的Torch文件转换为Onnx文件:
python tools/export_onnx.py --output-name yolox_1280.onnx -f .\exps\example\yolox_voc\yolox_voc_l_1280x.py -c D:\python\model\best_ckpt.pth
使用onnx2ncnn.exe将onnx转为ncnn格式模型文件onnx2ncnn.exe D:\python\YOLOX\yolox_1280.onnx model.param model.bin
此时会提示Unsupported slice step !因为注意力模块在ncnn中并不支持,所以需要自己在代码中实现这一层。
修改模型
打开model.param
7767517
359 406
Input images 0 1 images
Split splitncnn_input0 1 2 images images_splitncnn_0 images_splitncnn_1
Crop /backbone/backbone/stem/Slice 1 1 images_splitncnn_1 /backbone/backbone/stem/Slice_output_0 -23309=1,0 -23310=1,2147483647 -23311=1,1
Split splitncnn_0 1 2 /backbone/backbone/stem/Slice_output_0 /backbone/backbone/stem/Slice_output_0_splitncnn_0 /backbone/backbone/stem/Slice_output_0_splitncnn_1
Crop /backbone/backbone/stem/Slice_1 1 1 /backbone/backbone/stem/Slice_output_0_splitncnn_1 /backbone/backbone/stem/Slice_1_output_0 -23309=1,0 -23310=1,2147483647 -23311=1,2
Crop /backbone/backbone/stem/Slice_2 1 1 /backbone/backbone/stem/Slice_output_0_splitncnn_0 /backbone/backbone/stem/Slice_2_output_0 -23309=1,1 -23310=1,2147483647 -23311=1,2
Crop /backbone/backbone/stem/Slice_3 1 1 images_splitncnn_0 /backbone/backbone/stem/Slice_3_output_0 -23309=1,1 -23310=1,2147483647 -23311=1,1
Split splitncnn_1 1 2 /backbone/backbone/stem/Slice_3_output_0 /backbone/backbone/stem/Slice_3_output_0_splitncnn_0 /backbone/backbone/stem/Slice_3_output_0_splitncnn_1
Crop /backbone/backbone/stem/Slice_4 1 1 /backbone/backbone/stem/Slice_3_output_0_splitncnn_1 /backbone/backbone/stem/Slice_4_output_0 -23309=1,0 -23310=1,2147483647 -23311=1,2
Crop /backbone/backbone/stem/Slice_5 1 1 /backbone/backbone/stem/Slice_3_output_0_splitncnn_0 /backbone/backbone/stem/Slice_5_output_0 -23309=1,1 -23310=1,2147483647 -23311=1,2
Concat /backbone/backbone/stem/Concat 4 1 /backbone/backbone/stem/Slice_1_output_0 /backbone/backbone/stem/Slice_4_output_0 /backbone/backbone/stem/Slice_2_output_0 /backbone/backbone/stem/Slice_5_output_0 /backbone/backbone/stem/Concat_output_0 0=0
...我使用的是yolox-l,这看起来和官方给的转化demo有点不一样,但是实际上结构是完全相同的。
删除Input层后的10层,添加自定义层YoloV5Focus
YoloV5Focus focus 1 1 images /backbone/backbone/stem/Concat_output_0images输出到YoloV5Focus层,处理后再输出到/backbone/backbone/stem/Concat_output_0层。
再修改第二行的359层数为350,因为删除了10层并添加了一层。
在代码中实现YoloV5Focus
class YoloV5Focus : public ::ncnn::Layer
{
public:
YoloV5Focus()
{
one_blob_only = true;
}
virtual int forward(const ::ncnn::Mat& bottom_blob, ::ncnn::Mat& top_blob, const ::ncnn::Option& opt) const
{
int w = bottom_blob.w;
int h = bottom_blob.h;
int channels = bottom_blob.c;
int outw = w / 2;
int outh = h / 2;
int outc = channels * 4;
top_blob.create(outw, outh, outc, 4u, 1, opt.blob_allocator);
if (top_blob.empty())
return -100;
#pragma omp parallel for num_threads(opt.num_threads)
for (int p = 0; p < outc; p++)
{
const float* ptr = bottom_blob.channel(p % channels).row((p / channels) % 2) + ((p / channels) / 2);
float* outptr = top_blob.channel(p);
for (int i = 0; i < outh; i++)
{
for (int j = 0; j < outw; j++)
{
*outptr = *ptr;
outptr += 1;
ptr += 2;
}
ptr += w;
}
}
return 0;
}
};同时创建一个工厂函数用于ncnn来调用
inline ::ncnn::Layer* YoloV5Focus_layer_creator(void* /*userdata*/)
{
return new YoloV5Focus;
}或者使用ncnn提供的宏来创建
DEFINE_LAYER_CREATOR(YoloV5Focus)开始推理
主要代码还是看yolox提供的demo https://github.com/Megvii-BaseDetection/YOLOX/blob/main/demo/ncnn/cpp/yolox.cpp
我在这里就只解释一点内容。
ncnn的加速选项
开启Vulkan
首先安装Vulkan SDK或者Runtime,可以在https://vulkan.gpuinfo.org/ 查看显卡是否兼容,桌面端显卡现在也不会有老到不支持vulkan的卡把。
在模型加载前需要设置网络参数net.opt.use_vulkan_compute = true;
降低精度到fp16
ncnnoptimize.exe model.param model.bin yolox.param yolovx.bin 65536在支持高速fp16的显卡上推理可以大幅提升推理速度,但是较老的一些显卡可能没有fp16或者是低速fp16(比如英伟达的老卡)
低精度计算控制
默认为开启状态,可以手动设置关闭
net.opt.use_fp16_packed = false;
net.opt.use_fp16_storage = false;
net.opt.use_fp16_arithmetic = false;
net.opt.use_int8_storage = false;
net.opt.use_int8_arithmetic = false;由于我的办公电脑是1060 fp16有但是不多,提速不是很明显。
使用效果
对比OpenCV DNN和OpenCV + ncnn 在yolox-l输入大小为1280x1280的情况,循环多次查看效果。
DNN的推理速度,Forward是单纯的网络耗时:
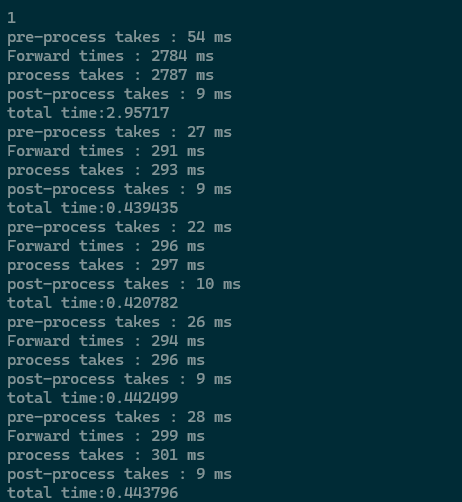
DNN
ncnn的网络耗时,未开启fp16的情况
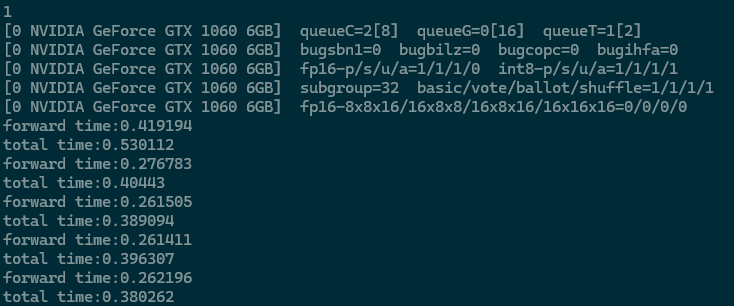
ncnn
ncnn 开启fp16后提升 10%左右
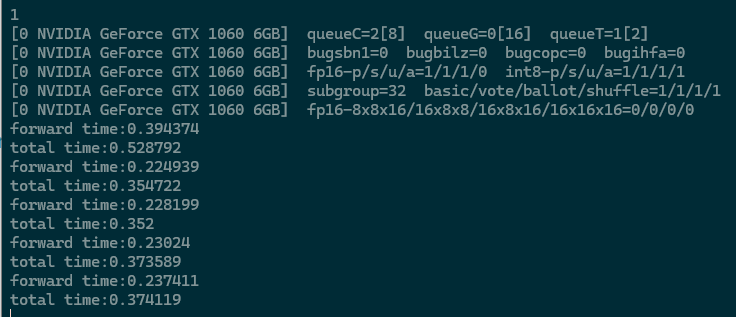
ncnn with fp16
除了首次推理需要加载模型权重以外,其他的推理时间可以看作真实情况。
观测dnn和ncnn的cpu和内存使用率
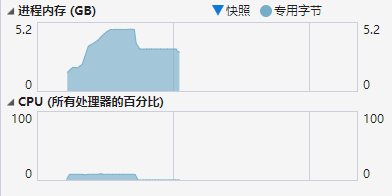
dnn cpu & mem
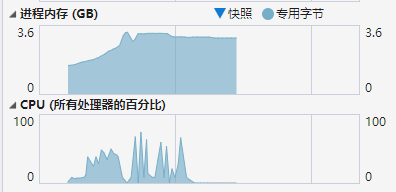
ncnn cpu & mem
对比下来可以看到ncnn对内存的压力有明显的优势,最高使用率降低了30%,同时ncnn对多线程优化比较好,推理速度稍微快dnn那么一丢丢,如果我的显卡支持fp16的话那么应该会更快。
因为ncnn不需要依赖第三方库(除了Vulkan),所以部署起来也是很方便,只用cpu推理就只要加入ncnn.dll一个文件就可以了。要显卡加速就装一个100多M的Vulkan,相比起来CUDA需要几个G来装CUDA Runtime,而且Vulkan不仅支持十多年前的老卡,甚至intel、AMD、Nvidia都是可以作为加速后端,这不比CUDA好用多了(虽然训练基本都还是要CUDA)。