LM Studio更好用的LLM部署工具以及使用代理的方法
最近本想使用一些视觉模型来处理一些图片,目前参数和性能对我的32G mac都比较合理的应该是Qwen2-vl int4量化模型,但是llama.cpp对这个视觉模型的支持还是停留在Draft的阶段,导致Ollama也没能对他提供支持。
至于vllm官方支持大头还是linux和cuda。
于是发现了另一款LM Studio,这款软件支持使用huggingface上的gguf和mlx格式模型。支持提供OpenAI兼容API,还自带一个Chat功能。确实比Ollama只能用CLI方便很多。
这款软件底层使用llama.cpp运行gguf,在Mac的M系列上还支持mlx,就是Apple专门为M系列推出的机器学习框架,因此使用LLM时能获得更好的加速效果。
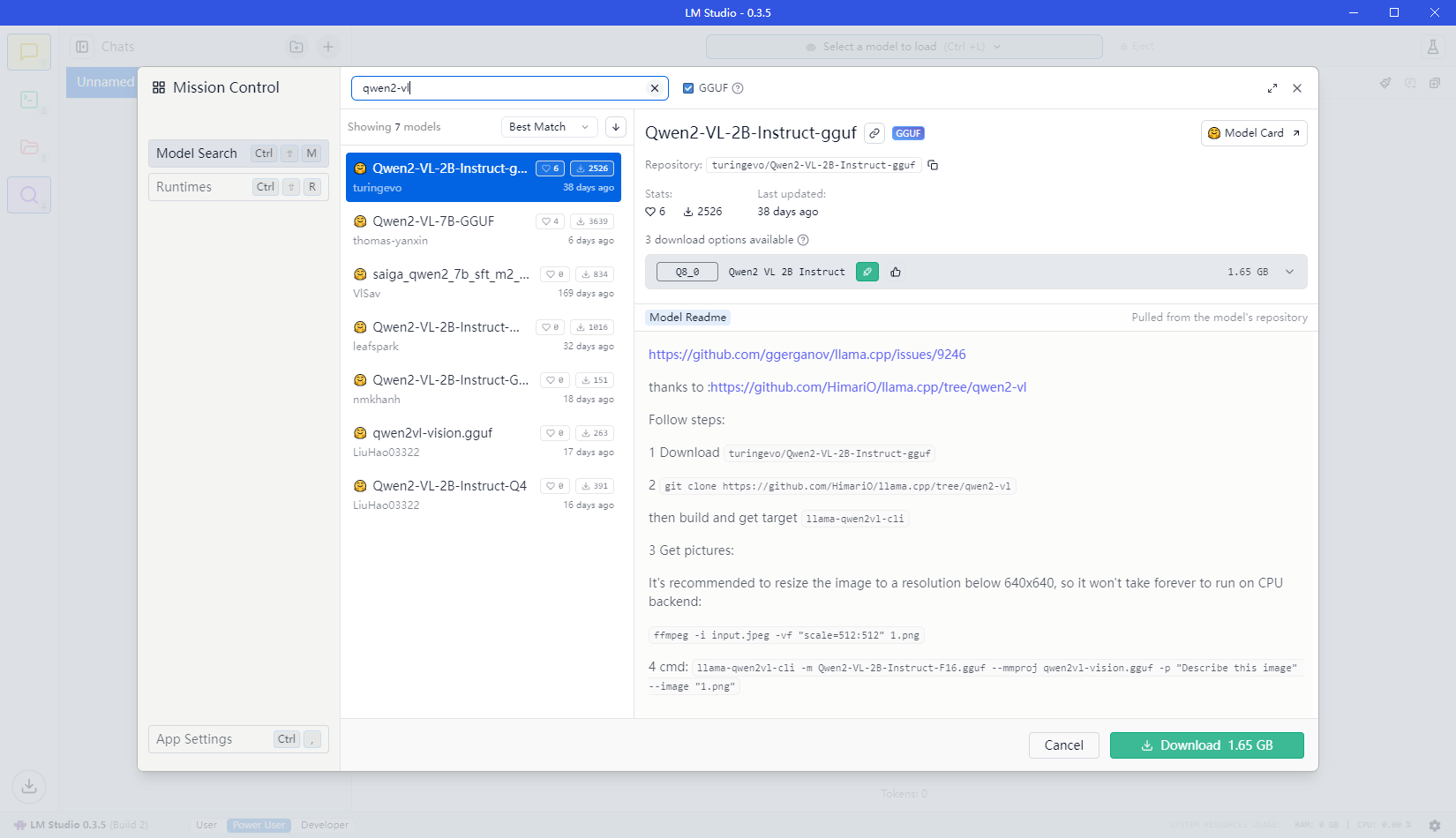
image.png
在我的Mac mini上先试验一下选择下载Qwen2-VL-7B-Int4模型,需要4.68G硬盘,无任务时占用4G,进行对话时最高总占用14G,16G的mini还是有些吃力啊。
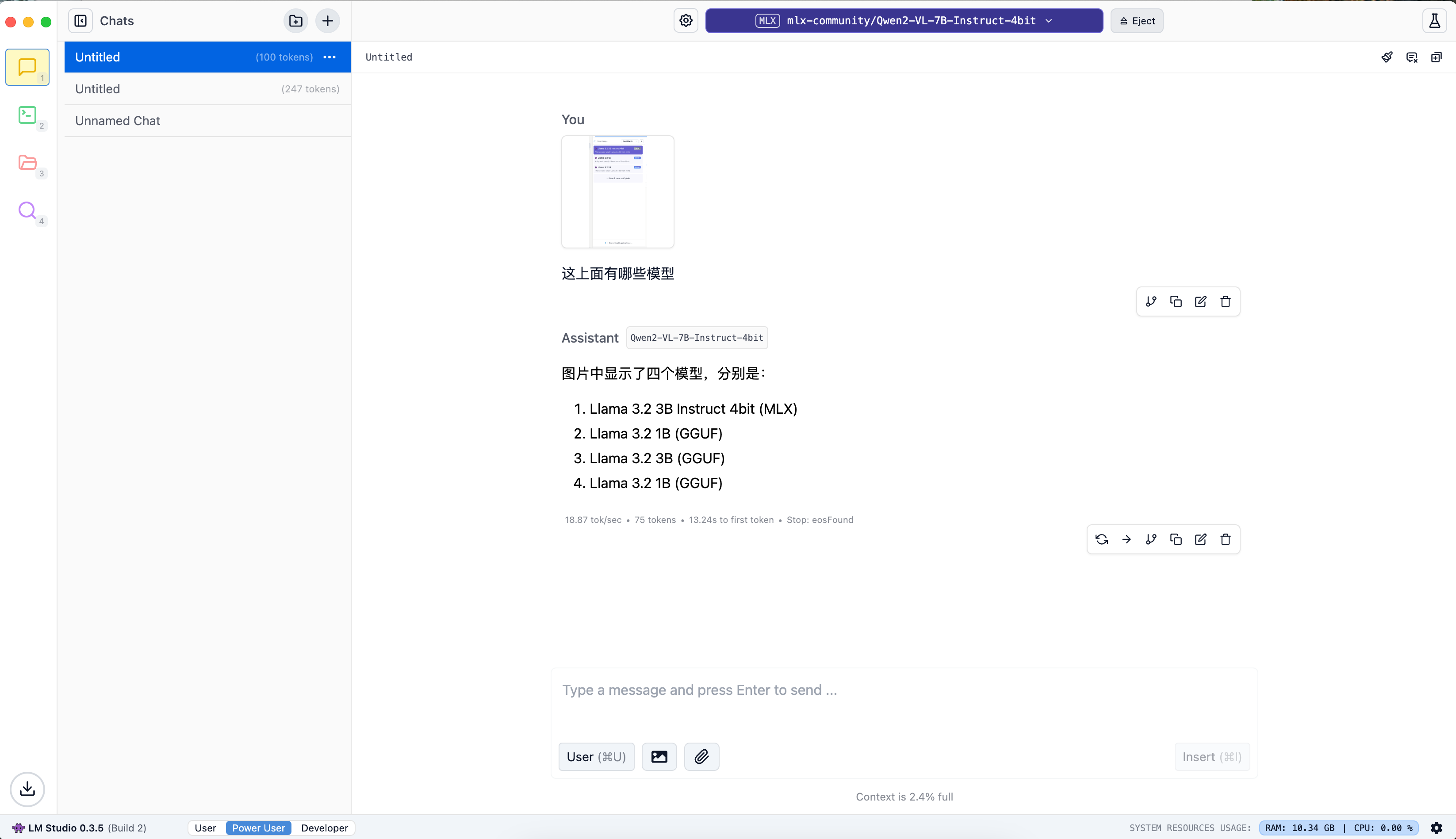
虽然内容识别正确还是像这些列表内容偶尔会重复输出,不知道是为什么。
使用代理
LM Studio程序中并未设置网络相关选项,但是好在联网部分只有使用huggingface,所以只需要替换掉所有的huggingface.co到国内可用的镜像hf-mirror.com,那么所有的请求都会通过hf-mirror来访问。
Mac 下
- 进入应用程序目录resources\app
- 同样进行替换
Windows 下
- C:\Users\Image\AppData\Local\LM-Studio\app-0.3.5\resources\app
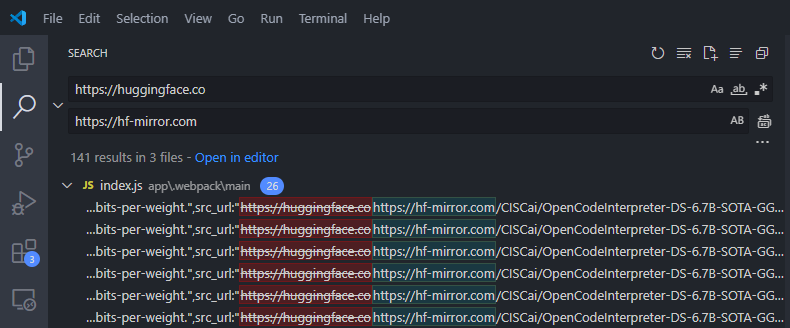
image.png
替换完重启软件,就能愉快的使用了