模型量化对模型精度影响的研究
前言
将模型量化到较低精度的格式(如8bit或4bit)可以显著降低计算成本并加速推理。然而,一直存在一个问题:这些量化的模型是否能保持相同的准确性和质量。最近,机器学习(ML)社区对量化的大型语言模型(LLMs)能否真正与其未压缩的版本在准确性和生成响应的整体质量上相竞争表示了重大关切。
正文
最近看到Neural Magic发布的一篇研究模型量化对于模型精度的影响的文章。
Neural Magic声称他们在自己的量化模型上进行了50万次的基准测试,包含常用的各种数据集。通过研究准确性的差异来回答前面的问题。
基于他们的实验结果,可以得出结论:量化模型与全精度模型没有明显的差异。
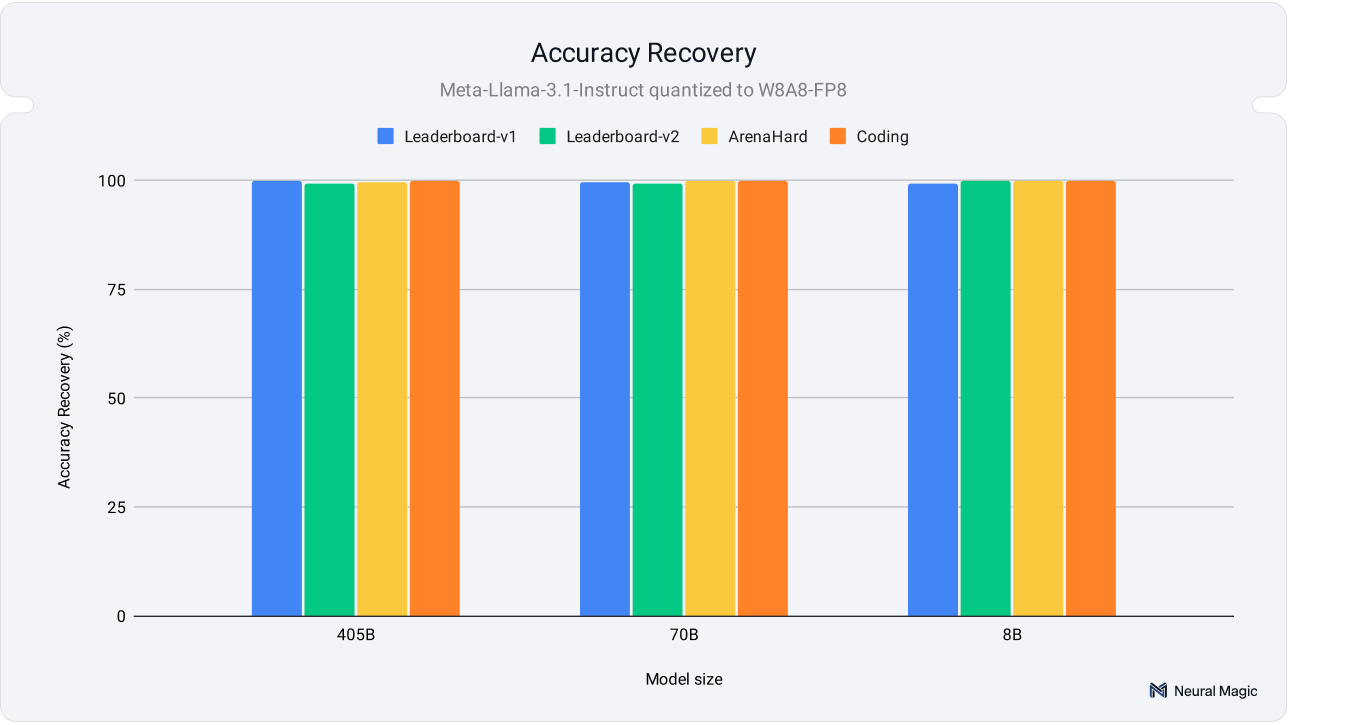
_Llama 3.1 模型在 FP8 精度下与全精度基线相比,在各种学术和现实世界评估基准测试中的准确性情况。
研究方法
对Llama3.1系列模型进行了广泛测试,所以这篇文章的数据依据是以Llama3.1为基准的(实际上他们不只对Llama3.1进行了测试,还测试了很多开源模型,可以在https://huggingface.co/collections/neuralmagic/vision-language-models-quantization-6724e415478a59591379f3e6看到具体的测试结果)。
在Llama3.1的405b、70b、8b模型使用W8A8-INT、W8A8-FP、W4A16-INT三种量化方法将模型将为int8、fp8和权重为int4激活层为16bit的模型。
具体的测试场景有:
- Academic Benchmarks 学术基准测试:如OpenLLM Leaderboard v1和v2,对于评估研究发展和模型改进至关重要。它们专注于结构化的任务,例如问答和推理,提供一致且易于验证的准确度分数。然而,它们往往无法反映在语义、多样性和上下文至关重要的现实世界场景中。
- Real-World Benchmarks 真实世界基准测试:与学术基准不同,真实世界基准测试在模仿人类使用场景(如指令遵循、聊天和代码生成)中检验模型。这些基准包括 ArenaHard 和 HumanEval,提供了更广泛且变化更大的任务组合,更好地反映了实际应用中的模型性能。这些基准为评估模型在实时环境中的表现提供了一个更为全面的视角。
- Text Similarity 文本相似度:文本相似度衡量量化模型的输出与其未量化的对应物之间匹配的紧密程度。诸如ROUGE)、BERTScore和语义文本相似性(STS)等指标评估语义和结构一致性,确保生成文本的预期意义和质量得以保留。
更详细的测试内容可查看原文,这里就不重复描述了。
总之
感谢Neural Magic对不同模型、不同参数、不同尺寸的量化模型进行了详细的测试,我们可以在这里总结:8bit和4bit的模型与全精度的模型相比性能损失很小,且更大的模型(如70b、405b)因量化带来的性能下降影响更小,与全精度模型相比,基本都在98%以上,部分场景测试更是99.9%的情况,几乎没有影响。
但是一些小模型(如8b)由量化带来的准确性波动会更大,但是“still preserve their outputs' core semantic meaning and structural coherence.”仍能保持其输出的核心语义含义和结构连贯性。
模型量化不仅能带来腰斩式的VRAM节省,同时还能带来明显的推理速度的提升,那么何乐而不为呢。