KTransformers 一个新型的Transformers框架能够有效提高LLM的推理速度
KTransformers通过内核优化和并行策略有效提升了token的吞吐速度,根据官方的测试,相比于llama.cpp基本都有1倍以上的提升,尤其是最近DeepSeek推出了DeepSeek V3和DeepSeek R1的MOE 671B的超大模型之后,KTransformers根据MOE的特性将稀疏矩阵运算层放入内存中,将剩下的稠密计算激活的专家放入VRAM中,可以做到单张14G显卡做到8.73token/s的推理速度。
简易接入流程
KTransformers 的核心是一个用户友好的基于模板的注入框架,它的定位和功能与llama.cpp、vllm一样提供与Transformers兼容的接口、RESTful API以及Web UI。它更注重本地受限资源情况下的部署,由清华大学MADSys组和Approaching.AI成员维护。
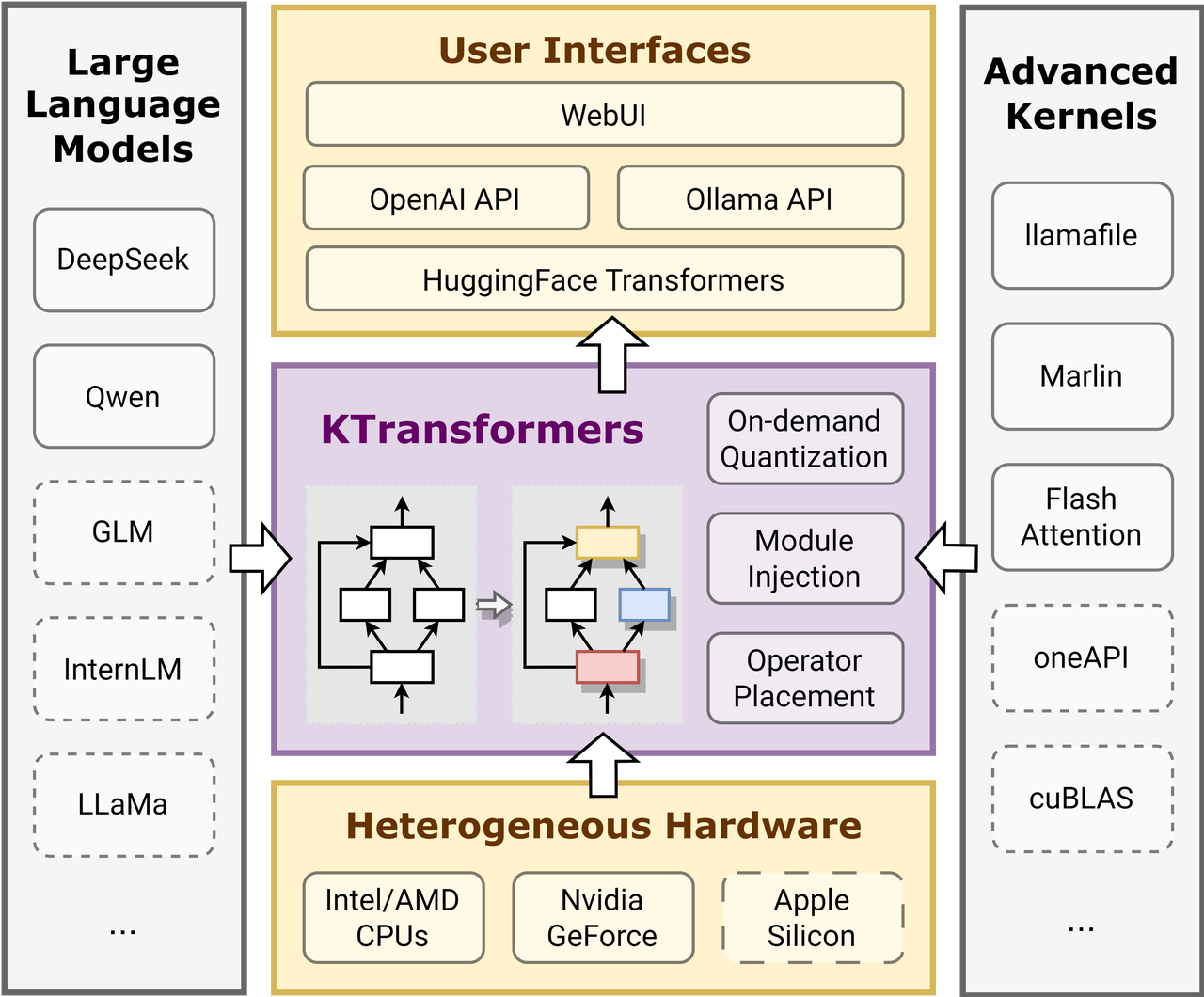
image.png
架构图如上,理论上可以很轻松的替换Transformers。
官方实践示例
官方在14GB VRAM 和 382GB DRAM的情况下成功运行了 Q4_K_M 671b版本的DeepSeek V3/R1。
- Prefill Speed (tokens/s):
预填充速度(令牌/秒):- KTransformers: 54.21 (32 cores) → 74.362 (dual-socket, 2×32 cores) → 255.26 (optimized AMX-based MoE kernel, V0.3 only) → 286.55 (selectively using 6 experts, V0.3 only)
KTransformers: 54.21(32 核)→ 74.362(双路,2×32 核)→ 255.26(优化基于 AMX 的 MoE 内核,仅 V0.3)→ 286.55(选择性地使用 6 个专家,仅 V0.3) - Compared to 10.31 tokens/s in llama.cpp with 2×32 cores, achieving up to 27.79× speedup.
与 llama.cpp 中的 2×32 核心相比,达到 10.31 tokens/s,速度提升高达 27.79 倍。
- KTransformers: 54.21 (32 cores) → 74.362 (dual-socket, 2×32 cores) → 255.26 (optimized AMX-based MoE kernel, V0.3 only) → 286.55 (selectively using 6 experts, V0.3 only)
- Decode Speed (tokens/s):
解码速度(个/秒):- KTransformers: 8.73 (32 cores) → 11.26 (dual-socket, 2×32 cores) → 13.69 (selectively using 6 experts, V0.3 only)
KTransformers: 8.73 (32 核) → 11.26 (双路,2×32 核) → 13.69 (选择使用 6 位专家,仅 V0.3 版) - Compared to 4.51 tokens/s in llama.cpp with 2×32 cores, achieving up to 3.03× speedup.
与 llama.cpp 中的 4.51 tokens/s 相比,在 2×32 核心上实现了高达 3.03 倍的速度提升。
- KTransformers: 8.73 (32 cores) → 11.26 (dual-socket, 2×32 cores) → 13.69 (selectively using 6 experts, V0.3 only)
快速使用参考内容:https://github.com/kvcache-ai/ktransformers/blob/main/doc/en/DeepseekR1_V3_tutorial.md#how-to-run
基础使用
待续...即使把需求降到了只要内存,但是还是没有大内存的机器可以用,无法实践。大家可以自己根据Installation Guide实践