Jina Reader-LM 将HTML转为Markdown的语言模型
Jina Reader-LM 是一系列将 HTML 内容转换为 Markdown 内容的模型,这对于内容转换任务非常有用。该模型在经过精心挑选的 HTML 内容及其对应的 Markdown 内容集合上进行了训练。并且有0.5b和1.5b大小的模型,简直是老头乐上都能运行。
- 许可证:CC-BY-NC-4.0
什么是Reader-LM
在2024年4月Jina推出了一个api,通过此接口可以将任意HTML网页转换为Markdown格式文本。
首先,我们使用无头 Chrome 浏览器获取网页源代码。然后,我们利用 Mozilla 的 [Readability](https://github.com/mozilla/readability) 包来提取主要内容,移除页眉、页脚、导航栏和侧边栏等元素。最后,我们使用 [regex](https://x.com/JinaAI_/status/1823756993108304135) 和 [Turndown 库](https://github.com/mixmark-io/turndown)将清理后的 HTML 转换为 markdown。最终得到的是一个结构良好的 markdown 文件,可供 LLM 用于知识增强、总结和推理。最开始的功能仅是由最基础的字符匹配去完成,但是社区的反应并不是很好,而且为了兼容和处理更多不同类型的网页,他们持续的往匹配规则上打补丁。最后想着这也不是个办法,最后提出了使用SLM(小语言模型)来完成这一项功能。
Reader-LM的发布
经过开发后在24年9月推出了第一代模型,支持256k的上下文长度,如此离谱的输入可以覆盖99.9%的网页类型了。特别是因为这个语言模型是专门为HTML转Markdown这一个任务而训练的,所以即使在0.5b和1.5b的大小下还是有不错的性能。
根据Jina的测试性能远超一众商业模型
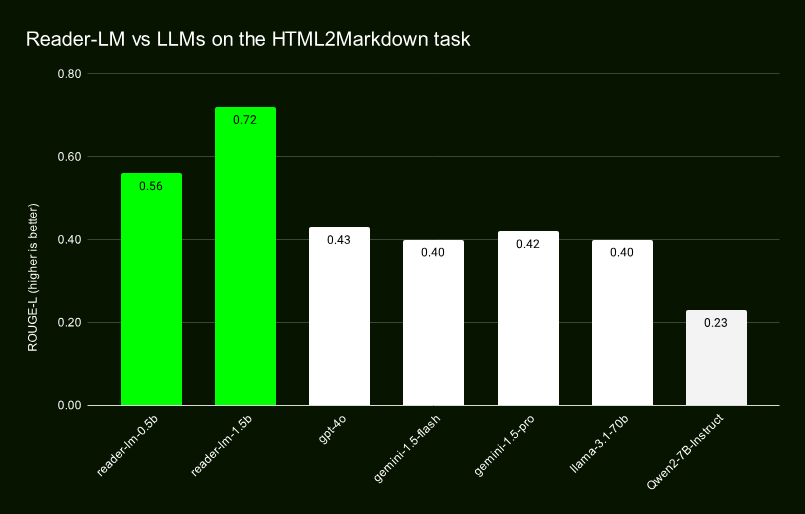
image.png
以下是这两个模型的规格:
| reader-lm-0.5b | reader-lm-1.5b | |
|---|---|---|
| # Parameters | 494M | 1.54B |
| Context length | 256K | 256K |
| Hidden Size | 896 | 1536 |
| # Layers | 24 | 28 |
| # Query Heads | 14 | 12 |
| # KV Heads | 2 | 2 |
| Head Size | 64 | 128 |
| Intermediate Size | 4864 | 8960 |
| Multilingual | Yes | Yes |
| HuggingFace Repo | Link | Link |
V2发布内容
最近发布了他的V2版本与第一版相比的改动:
- 上下文长度:256k -> 512k
- 输出格式:文本(Markdown)-> 文本(Markdown)、文本(JSON) ReaderLM的输出长度并没有像其他模型一样有4K或者8K的限制,而是输入输出共享512K的长度。 ## V2的性能测试
在语言模型飞速进化的2024年,所有的模型各项性能都在大步飞升,各种模型均有超过reader-lm的趋势。
不过V2的发布将这一优势继续放大
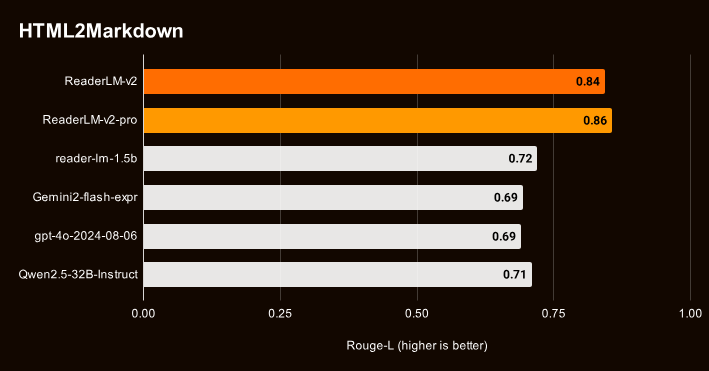
image.png
Jina也顺势推出了ReaderLM-v2-pro一个共给企业使用的优化版本。
如何训练的ReaderLM-v2
ReaderLM-v2 基于 Qwen2.5-1.5B-Instruction(Qwen确实很强,因为出色的性能,以及同时推出了针对不同领域的微调模型和不同尺寸的模型,所以在各种地方都能见到他的身影,应该是2024年影响力最大的开源模型了)
基础信息
| Model Parameter | ReaderLM-v2 |
|---|---|
| Total Parameters | 1.54B |
| Max Context Length (Input+Output) | 512K |
| Hidden Size | 1536 |
| Number of Layers | 28 |
| Query Heads | 12 |
| KV Heads | 2 |
| Head Size | 128 |
| Intermediate Size | 8960 |
| Multilingual Support | 29 languages |
| HuggingFace Repository | Link |
训练数据集的获得
Jina创建了 html-markdown-1m 数据集,其中包括从互联网收集的一百万个 HTML 文档。平均而言,每个文档包含 56,000 个token。在准备这个数据集时,通过删除不必要的元素来清理 HTML 文件,同时保留关键的结构和语义元素。清理后,使用 Jina Reader通过正则表达式模式和启发式方法将 HTML 文件转换为 Markdown。
但是他们发现如果只是使用正则匹配来的数据,最后训练出来的模型只会模仿正则匹配模式。因此他们引入了 Qwen2.5-32B-Instruction来合成数据。
1. **起草**:我们基于提供给模型的指令生成初始 Markdown 和 JSON 输出。这些输出虽然多样,但常常包含噪音或不一致。
2. **改进**:通过删除冗余内容、强化结构一致性并与所需格式对齐来改进生成的草稿。这一步确保数据清洁并符合任务要求。
3. **评估**:将改进后的输出与原始指令进行评估。只有通过评估的数据才会被纳入最终数据集。这种迭代方法确保训练数据达到结构化数据提取所需的质量标准。简单来说,那就是先第一次提取,之后再输入原HTML和第一次输出的Markdown进行优化,最后再输入HTML和第二次输出的Markdown进行验证是否合格。
这个合成数据的流程还挺有意思的,可以记录一下说不定以后会用到。
使用ReaderLM
由于本篇编写的时候V2刚发布,ollama还没有V2的版本。
想要用的话可以使用llama.cpp将其转化为gguf格式直接导入就可以,参照我之前的折腾llama 405b过程。
我图省事我就直接用lm studio部署了别人量化好Q4的gguf版本。
image.png
然后在模型设置页面修改输入context最大长度到512k!
image.png
然后就爆内存了,32G对于512k来说还是太mini了。
在使用128k上下文的时候载入需要大约5G内存,尝试处理一个网页86220 tokens,耗时690s。m2 pro 丐版的GPU还是太弱了。不过提取的质量很高。
总结
尽管在处理大规模上下文时对硬件资源要求较高普通显卡的话,还是推荐先使用基础方式剔除一些不需要的内容在交给它处理,虽然耗时很长但 ReaderLM 在内容转换任务中的表现依然令人满意。